
こちらのページでは、ML-Agentsの公式サンプルに入っています、「Basic」についての解説ページになります。
「Basic」は「Agent」(立方体)を左右に移動させて「ゴール」(球)に到達させよう!というゲームになります。ゲーム自体は非常に単純なので、ML-Agents特有のスクリプト構造の基本を学ぶのに最適なサンプルになります。なので、このサンプルで仕組みをしっかりおさえていきましょう。
なお、本ページはML-Agents(ver0.5)に基づいて解説していきます。2018年12月17日に、ML-Agents(ver0.6)が新規にリリースされました。ver0.6では、Brain Typeの設定方法が大きく変更されております。設定方法についてはこちらのページにまとめましたので、ML-Agents(ver0.6)でサンプルをいじる際は本ページと併せて参考にして下さい。
まずは自分で遊んでみよう
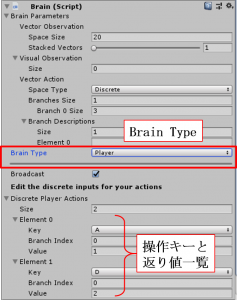 とりあえず、どんなゲームかを体感するために自分で遊んでみましょう。右図は「Academy」の子オブジェクト「Basicbrain」の設定画面になります。まず、自分で遊ぶ場合は「Brain Type:Player」に設定して下さい。操作キーは下の方に書かれているように、
とりあえず、どんなゲームかを体感するために自分で遊んでみましょう。右図は「Academy」の子オブジェクト「Basicbrain」の設定画面になります。まず、自分で遊ぶ場合は「Brain Type:Player」に設定して下さい。操作キーは下の方に書かれているように、
・「A」:値「1」を返す
・「D」:値「2」を返す
です。これだけでは何のことかさっぱり分かりませんが、後で解説しますようにスクリプト(BasicAgent.cs)を見ると、
・「A」:「Agent」が左移動
・「D」:「Agent」が右移動
に対応しています。また、さらにスクリプトを読むと分かりますが、1回左右移動すると報酬-0.01、左の小球にゴールすると報酬+0.1、右の大球にゴールすると報酬+1、が入る仕組みになっており、これからいかに少ない移動回数で(出来れば右側に)ゴールするか、というゲームになっていることが分かります。
次に、機械学習させてみよう
では次に、このゲームを機械学習させてみましょう。先程も見ました「Basicbrain」の設定画面にて、今度は「Brain Type:External」にして機械学習を実行します(実行のための詳細手順はコチラのページを参照)。
機械学習の最初の方では↓のように、「Agent」がなかなかゴールに向かうことなくめっちゃ道中でウロウロしていますね…。目的もよく分からず、アタフタしている感じです。これはこれでカワイイけど…(笑)

(注:上の動画は機械学習のオプションに「--slow(通常速度で学習実行)」を入れて実行したものを撮影しています)
次に、10万ステップ程学習した後の動きを見てみましょう。↓のようになります。迷いなく、速攻で右に向かっていきますね。確かに機械学習の効果が現れており、「Agent」はゲームの目的を充分理解してくれているようです。…何か最初のアタフタしている感じが無くなって逆にカワイくないですけど…(笑)。

スクリプトの中身について
この「Basic」には、3つのスクリプト(BasicAcademy.cs、BasicAgent.cs、BasicDecision.cs)が付いております。各スクリプトの概要についてはサンプル集解説0にて書いた通りですが、今回のスクリプトの主役は「Agent」に実装している「BasicAgent.cs」になりますので、これの中身を解説していきます。
とは言え、今回のゲームは比較的簡単なものなので、ML-Agents特有のクラス「Agent」の基本に重点を置いて解説していきます!
サンプル集解説0にて書きましたが、「Agent」に付けるスクリプトは「Agent」クラスを継承しており、5つの(オーバーライド)メソッドを持っているんでしたね。では、各メソッドの詳細を見ていきましょう。
<①void InitializeAgent()メソッド:初期化時呼び出し>
通常のUnityで出てくるMonoBehaviorクラスのStartメソッドのような感じですね。通常のUnityでもオブジェクトを検索するFindメソッドはStartメソッド中に書くのが通例ですが、それと同様、今回も本メソッド内にFindメソッドが書かれています。
<②void AgentReset()メソッド:エピソード終了時呼び出し>
エピソード終了時(④より「Agent」がゴールした時に対応)に、呼び出されるメソッドです。今回の場合、エピソード終了時には場面がリセットされ、各オブジェクトが初期配置に戻される手続きがなされています。
<③void CollectObservations()メソッド:State取得時に呼び出し>
④のメソッドで「Agent」が行動した結果の状態をBrain(「Brain Type:External」の場合はAI)に返していきます。返すのはAddVectorObs()メソッドを使います。今回の場合、「Agent」の位置座標をBrainに返しております。
<④void AgentAction(float[] vectorAction, string textAction)メソッド:ステップ毎に呼び出し>
 本メソッドではまず、「Agent」の行動を決定していきます。右図の設定画面中の下側(Vector Action以下)より「Branch 0 Size:3」となっていますので、スクリプト中のvectorAction[0]=0~2が入り、「Agent」の行動が決まります。今回の場合、以下のスクリプトより、最初に説明しました通り、vectorAction[0]=1で左移動、vectorAction[0]=2で右移動、になりますね。
本メソッドではまず、「Agent」の行動を決定していきます。右図の設定画面中の下側(Vector Action以下)より「Branch 0 Size:3」となっていますので、スクリプト中のvectorAction[0]=0~2が入り、「Agent」の行動が決まります。今回の場合、以下のスクリプトより、最初に説明しました通り、vectorAction[0]=1で左移動、vectorAction[0]=2で右移動、になりますね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
var movement = (int)vectorAction[0]; int direction = 0; switch (movement) { case 1: direction = -1; break; case 2: direction = 1; break; } position += direction; if (position < minPosition) { position = minPosition; } if (position > maxPosition) { position = maxPosition; } gameObject.transform.position = new Vector3(position - 10f, 0f, 0f); |
また、本メソッド中での報酬が与えられる仕組みは以下のようになります。AddReward(○○)で○○の報酬を「Agent」に与えます。これを見ると、最初に書きましたように、1回左右移動で報酬-0.01、左の小球ゴールで報酬+0.1、右の大球ゴールで報酬+1、であることが分かります。
Done()はエピソードの完了を表しAgentReset()メソッドが発動します。下のスクリプトからも、どちらかのゴールに到着するとエピソード完了であることが分かりますね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
AddReward(-0.01f); if (position == smallGoalPosition) { Done(); AddReward(0.1f); } if (position == largeGoalPosition) { Done(); AddReward(1f); } |
<⑤void AgentOnDone()メソッド:エピソード完了時に呼び出し>
今回は使用していません。
<⑥他メソッド>
FixedUpdateメソッド(=1秒間に固定回数呼び出し)中にRequestDecision()メソッドが使用されています。「Agent」の「On Demand Decisions」にチェックが入っていますので、RequestDecision()メソッドが通った時のみActionが決定されます。