
こちらのページでは、ML-Agentsの公式サンプルに入っています、「GridWorld」についての解説ページになります。
「GridWorld」は「Agent」(青□)を上下左右に上手く操作して「pit」(落とし穴、橙×)に落ちないように「goal」(ゴール、緑+)に到着しよう!というゲームになります。前々回の「Basic」や前回の「3DBall」のサンプルとは異なり、「Visual Observation」による学習=特定のCameraから見える視覚情報から機械学習を行うサンプルになっています。
なお、本ページはML-Agents(ver0.5)に基づいて解説していきます。2018年12月17日に、ML-Agents(ver0.6)が新規にリリースされました。ver0.6では、Brain Typeの設定方法が大きく変更されております。設定方法についてはこちらのページにまとめましたので、ML-Agents(ver0.6)でサンプルをいじる際は本ページと併せて参考にして下さい。
まずは自分で遊んでみよう
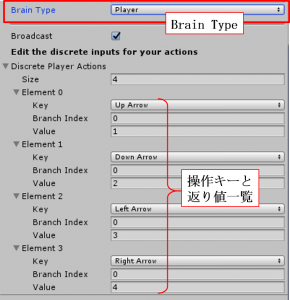 とりあえず、どんなゲームかを体感するために自分で遊んでみましょう。右図は「GridAcademy」の子オブジェクト「GridWorldBrain」の設定画面になります。いつものように、「Brain Type:Player」にして遊びましょう。操作キーは右図にあるように、
とりあえず、どんなゲームかを体感するために自分で遊んでみましょう。右図は「GridAcademy」の子オブジェクト「GridWorldBrain」の設定画面になります。いつものように、「Brain Type:Player」にして遊びましょう。操作キーは右図にあるように、
・「↑」:vectorAction[0]に値「1」を返す
・「↓」:vectorAction[0]に値「2」を返す
・「←」:vectorAction[0]に値「3」を返す
・「→」:vectorAction[0]に値「4」を返す
です。後で解説しますようにスクリプト(GridAgent.cs)を見ると、以下のように対応していることが分かります。
・「↑」:「Agent」(青□)が上に1マス移動
・「↓」:「Agent」(青□)が下に1マス移動
・「←」:「Agent」(青□)が左に1マス移動
・「→」:「Agent」(青□)が右に1マス移動
ちなみにスクリプトより、落とし穴にハマると報酬-1、ゴールすると報酬+1、各ステップ報酬-0.01、が入る仕組みになっており、これからいかに落とし穴にハマることなく、短時間でゴールに到着出来るか、というゲームになっていることが分かります。
人がプレイする分には特に難しくないゲームですが、適当にランダムに進んでいたらうっかり落とし穴にはまってしまいそうなゲームですね。機械がこのゲームをプレイしても、適当に進んでうっかり落とし穴…とかなってしまいそうですが…、どうなるでしょうか??
次に、機械学習させてみよう
では次に、「Brain Type:External」にしてこのゲームを機械学習させてみましょう(実行のための詳細手順はコチラのページを参照)。
機械学習の最初の方では↓のように、「Agent」がなかなかゴールに向かわずに、道中でウロウロしています。ゴール近くで無駄にウロウロしてなかなかゴールしなかったり、うっかり落とし穴にハマっていますねー。

(注:上の動画は機械学習のオプションに「--slow(通常速度で学習実行)」を入れて実行したものを撮影しています)
次に、20万ステップ程学習した後の動きを見てみましょう。↓のようになります。迷いなくゴールに向かっていきますね。スタート位置がゴールから遠い場合でも一直線に向かっていきますし、落とし穴はしっかり避けていきます。確かに機械学習の効果が現れており、「Agent」はゲームの目的をしっかり理解しているようです。スゴイ…。

スクリプトの中身について
この「GridWorld」には、2つのスクリプト(GridAcademy.cs、GridAgent.cs)が付いております。各スクリプトの概要についてはサンプル集解説0にて書いた通りで、今回のサンプルスクリプトはどちらも中身がしっかり書かれていますので、両者の中身をそれぞれ解説していきます。
解説の都合上、「GridAcademy.cs」→「GridAgent.cs」の順に解説していきます。
スクリプト解説1「GridAcademy.cs」
サンプル集解説0にて書きましたが、「Academy」に付けるスクリプトは「Academy」クラスを継承しており、3つの(オーバーライド)メソッドを持っているんでしたね。では、各メソッドの詳細を見ていきましょう。
<①void InitializeAcademy()メソッド:環境初期化時に呼び出し>
通常のUnityで出てくるMonoBehaviorクラスのStartメソッドと同様、様々な初期設定を行っています。特に、「配列Objectsの、Objects[0]="Agent"(青□)、Objects[1]="goal"(緑+)、Objects[2]="pit"(橙×)のprefab」であることはおさえておきましょう。
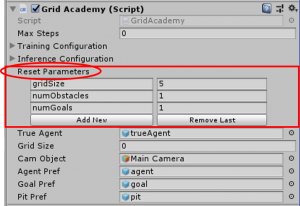 また、(int)resetParameters["gridSize"]というメソッドが新たに出て来ましたが、これは右の「Academy」の設定画面中で、赤□で囲んである部分にあります、resetParametersという箇所で設定出来る数値を呼び出せるメソッドになっております。要するに、通常のスクリプトで「public int」みたいに変数定義すると、スクリプト外から変数の値を設定出来るのと同様に考えて下さい。本メソッドは次のAcademyResetメソッド中にも使われますので、よくおさえておきましょう。
また、(int)resetParameters["gridSize"]というメソッドが新たに出て来ましたが、これは右の「Academy」の設定画面中で、赤□で囲んである部分にあります、resetParametersという箇所で設定出来る数値を呼び出せるメソッドになっております。要するに、通常のスクリプトで「public int」みたいに変数定義すると、スクリプト外から変数の値を設定出来るのと同様に考えて下さい。本メソッドは次のAcademyResetメソッド中にも使われますので、よくおさえておきましょう。
<②void AcademyReset()メソッド:環境リセット時に呼び出し>
本メソッド中(と、途中で参照するSetEnvironmentメソッド)には幾つか重要な動的配列が使用されていますので、まずはそれらの名称と役割をそれぞれご紹介!
・playersList:場に挿入するオブジェクトの番号リスト(1:pit、2:goalに対応)→リストが完成次第、配列playersにコピー
・numbers:場に挿入するオブジェクトの設置場所番号リストを作成(本リストのn要素目は配列playersのn要素目のオブジェクトの設置位置番号が入る)→リストが完成次第、配列numbersAにコピー
・actorObjs:配列playersの番号リストに対応するオブジェクトの動的配列
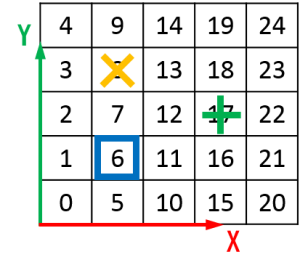 例として、上で示した(デフォルト)設定の場合ですと、"goal"(Object番号1)、"pit"(Object番号2)共に1個ずつの配置なので、配列players={2,1}になります。
例として、上で示した(デフォルト)設定の場合ですと、"goal"(Object番号1)、"pit"(Object番号2)共に1個ずつの配置なので、配列players={2,1}になります。
次に、各要素の配置位置を決定します。各位置には右のような番号が割り振られており、各オブジェクトにランダムに番号を割り当て、その番号に対応する位置に配置します。例えば、配列numbersA={8,17,6}と選ばれた場合、先程の配列playersの要素と比較して、
・players[0]=2:pit(落とし穴)は位置numbersA[0]=8に配置
・players[1]=1:goal(ゴール)は位置numbersA[1]=17に配置
・Agent(主人公)は位置numbersA[2(:最後の要素)]=6に配置
結果、上図のように配置される、という仕組みになっています。なお、動的配列numbersは「HashSet<int> numbers」と定義されており、これにより要素の重複を防いでくれる→別要素が同位置に配置されるのを防ぐ、という仕組みになっております。よく出来ていますね。
今回のAcademyReset()メソッドは色々複雑なことが書かれているように見えますが、中身の概要はこんな感じです。
<③void AcademyStep()メソッド:ステップ毎に呼び出し>
今回は特に使用されていませんね。
スクリプト解説2「GridAgent.cs」
サンプル集解説0にて書きましたが、「Agent」に付けるスクリプトは「Agent」クラスを継承しており、5つの(オーバーライド)メソッドを持っているんでしたね。では、各メソッドの詳細を見ていきましょう。
<①void InitializeAgent()メソッド:初期化時呼び出し>
通常のUnityで出てくるMonoBehaviorクラスのStartメソッドと同様ですね。今回もFindメソッドが本メソッド内で使用されています。
<②void AgentReset()メソッド:エピソード終了時呼び出し>
AcademyのAcademyResetメソッドを呼び出しています。リセット時の処理はAcademyResetメソッドに全て書かれておりますのでそちらを参照。
<③void CollectObservations()メソッド:State取得時に呼び出し>
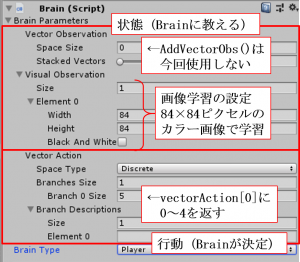 最初に書きました通り、本サンプルは「Visual Observation」による機械学習になりますので、AddVectorObs()メソッドを用いてAgentの状態をBrainに返すことを実施しておりません。ちなみに、「Visual Observation」の設定は右のような具合になります。
最初に書きました通り、本サンプルは「Visual Observation」による機械学習になりますので、AddVectorObs()メソッドを用いてAgentの状態をBrainに返すことを実施しておりません。ちなみに、「Visual Observation」の設定は右のような具合になります。
ただ、SetMaskという別メソッドが呼び出されており、そちらではSetActionMask()メソッドが使用されております。こちらはML-Agents特有のメソッドになりまして、「Brain Type:External、Internal」の場合に、SetActionMask(○)使用時→④中のvectorAction[X]の出力値として○を選択せずに、それ以外から選択される、というメソッドになります。なお、本メソッドを有効にするには「trueAgent」設定画面内の「Mask Action」にチェックを付ける必要があります。ご注意下さい。
後の④と併せてスクリプトを読めば分かりますが、要するに壁を越えて移動するのはNG、ということです。壁越えNGというのは後の④中のスクリプトでも書かれていますが、SetActionMask()メソッドも併せて使用すれば機械学習の効率がより良くなる、ということでしょうか?便利なメソッドですね。
<④void AgentAction(float[] vectorAction, string textAction)メソッド:ステップ毎に呼び出し>
まず「Agent」の行動決定についてですが、上図の設定画面中のVector Action以下より「Branch 0 Size:5」となっていますので、スクリプト中のvectorAction[0]=0~4が入り、「Agent」の行動が決まります。スクリプトを見ると分かりますが、最初に説明しました通り、vectorAction[0]=1:上、2:下、3:左、4:右移動、になっていますね。
ただ、本当に移動するかどうかは以下のif文の条件を満たした場合のみになります。上の③でも触れましたが、壁越えはNG、という話です。「Brain Type:External、Internal」の場合は③でのSetActionMask()メソッドで対応出来ますが、それ以外の場合、つまり「Brain Type:Player、Heuristic」の場合はSetActionMask()メソッドでは対応出来ませんので、本メソッド内でも壁越えNGのスクリプトが書かれているって話ですね。
本サンプルでは壁オブジェクト(「sE」とか…タグ「wall」が付いてる)や「Agent」にはColliderが付いており、これを利用して、壁越えしていないかを管理します。具体的には、変数targetPosが、vectorAction[0]の値により決まる、Agentの移動(予定)先座標になりますので、まず以下スクリプトの1行目で移動(予定)先の座標に新規Colliderを作成し、2行目のif文で新規Colliderが壁と干渉していないかチェックしています。干渉していない場合は、4行目で無事移動(予定)先に移動出来るって流れですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Collider[] blockTest = Physics.OverlapBox(targetPos, new Vector3(0.3f, 0.3f, 0.3f)); if (blockTest.Where(col => col.gameObject.CompareTag("wall")).ToArray().Length == 0) { transform.position = targetPos; if (blockTest.Where(col => col.gameObject.CompareTag("goal")).ToArray().Length == 1) { Done(); SetReward(1f); } if (blockTest.Where(col => col.gameObject.CompareTag("pit")).ToArray().Length == 1) { Done(); SetReward(-1f); } } |
また、報酬については(AddReward(○○):○○の報酬を「Agent」に与える)、上スクリプトより、落とし穴にハマる(←"pit"と干渉)と報酬-1、ゴールする(←"goal"と干渉)と報酬+1、各ステップ報酬-0.01、ですね。そして、Done():エピソードの完了なので、スクリプトより、落とし穴にハマるorゴールするとエピソード完了となります。
<⑤void AgentOnDone()メソッド:エピソード完了時に呼び出し>
今回は使用していません。
<⑥他メソッド>
FixedUpdateメソッドが使用されています。中身は「Basic」サンプルでのFixedUpdateメソッドの中身と全く一緒になりますので、解説はこちらの最後の方を参照下さい。